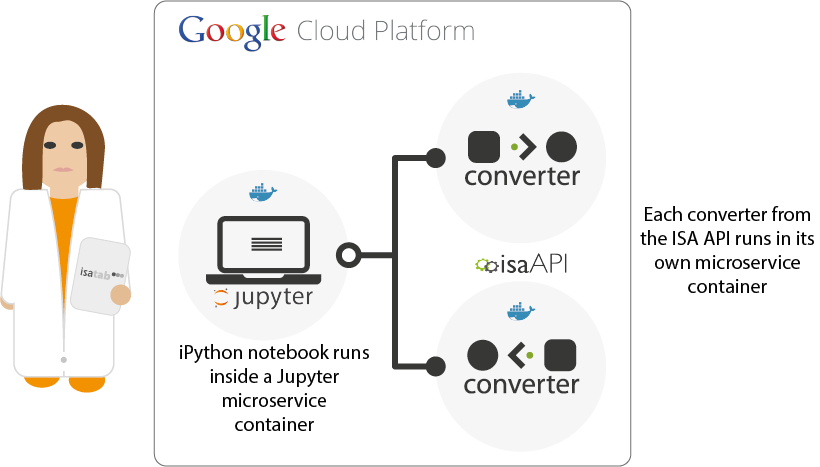
We’re very pleased to announce today the version 0.5 release of the Python ISA API, where the work started almost 2 years ago.
The ISA API aims to provide software developers with a set of tools to help you easily and quickly build your own ISA objects, validate, and convert between serializations of ISA-formatted datasets and other formats/schemas (e.g. SRA schemas). The ISA API is published on PyPI as the isatools package. The vision for the ISA API is to provide a programming library that will become the core for all software tooling that supports the ISA framework. It enables the import of various data formats into an implementation of the ISA Abstract Model as Python objects, and export of ISA content from Python objects back to different serialization formats.
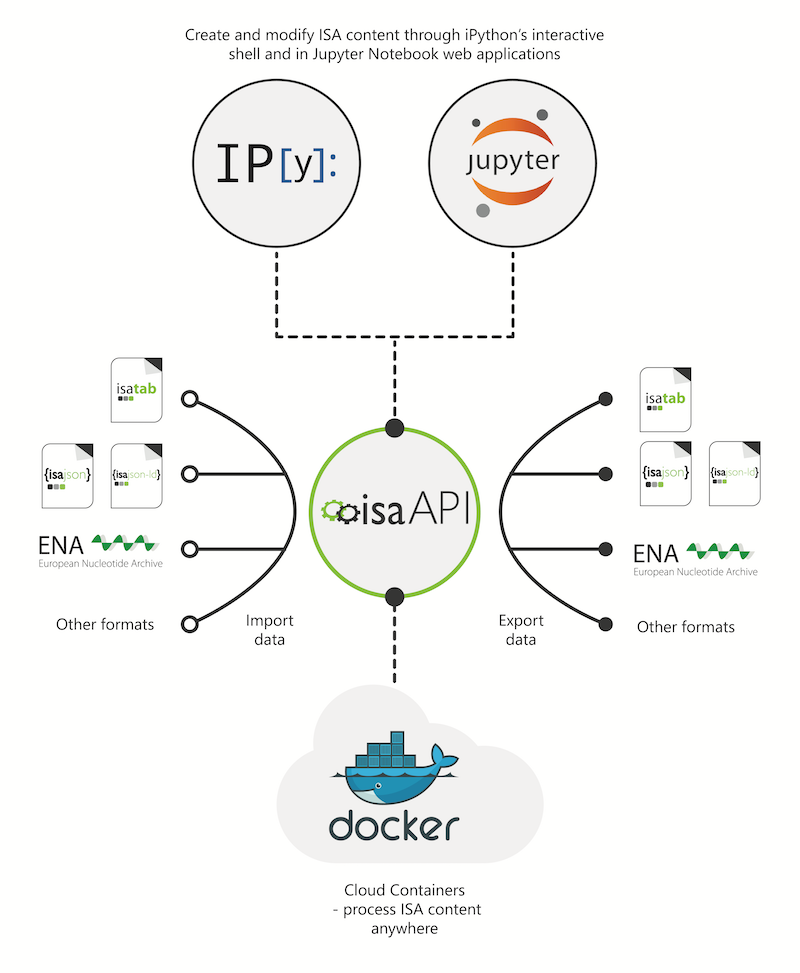 Currently we support import of ISA-Tab, ISA JSON, SRA XML (European Nucleotide Archive), Metabolomics Workbench, Biocrates XML and mzML formats, and export to ISA-Tab, ISA JSON and SRA XML. Beyond enabling I/O of data, the ISA API also supports programmatic creation of ISA content through the Python ISA model objects directly, thus then being able to export ISA content in the aforementioned serialization formats. This means that you can use the ISA API in your own software tools to create ISA-Tab and ISA JSON. You can see the ISA API in action in this example creating a simple ISA-Tab.
Currently we support import of ISA-Tab, ISA JSON, SRA XML (European Nucleotide Archive), Metabolomics Workbench, Biocrates XML and mzML formats, and export to ISA-Tab, ISA JSON and SRA XML. Beyond enabling I/O of data, the ISA API also supports programmatic creation of ISA content through the Python ISA model objects directly, thus then being able to export ISA content in the aforementioned serialization formats. This means that you can use the ISA API in your own software tools to create ISA-Tab and ISA JSON. You can see the ISA API in action in this example creating a simple ISA-Tab.
Since the ISA API is available as a Python library in the isatools PyPI package (just install with pip install isatools), it can easily be integrated with Python ecosystem infrastructure such as iPython’s interactive computing environment and Jupyter, a web application that allows you to create and share documents that contain live Python code are more. We are also developing ISA API containers using Docker, via the Horizon 2020 PhenoMeNal project, to run various function from the isatools package on the Cloud.
This version 0.5 release marks a significant milestone as the ISA Team has put a lot of effort into developing various I/O and ISA content creation features. Now we are looking to scale up and make robust the ISA API with thorough performance and user testing as we work towards a version 1.0 release.
The ISA API is still in development and as an open-source project we would be very happy to receive any help and code contributions (testing, feature requests, pull requests). Please feel free to contact our development team at isatools@googlegroups.com or on the ISA Community Forum Google Group, or ask a question, report a bug or request a new feature in the GitHub issue tracker.
Read more:
- Documentation: http://isatools.readthedocs.io
- GitHub project: https://github.com/ISA-tools/isa-api
- GitHub issues: https://github.com/ISA-tools/isa-api/issues
- Python Package Index: https://pypi.python.org/pypi/isatools
- All about ISA: http://isa-tools.org