Over the last few months, the ISA Team has been working hard on editing a long-awaited release of the ISA Model and Serialization Specifications 1.0.
The original ISA-Tab specification was published as a Release Candidate document in 2008, documenting the initial work that forms the ISA framework, with a further update in 2009. Since then, we have done work on a new serialization in JSON, ISA-JSON, and abstracted out the data model from both the tabular and JSON formats.
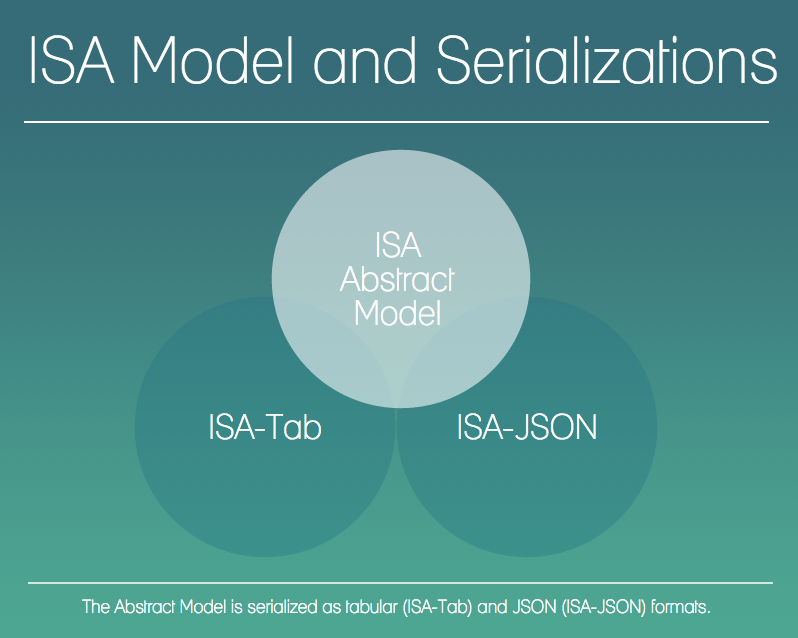
The ISA Model and Serialization Specifications consist of three specification documents:
- ISA Abstract Model – a data model of ISA objects/entities and their relation to one another
- ISA-Tab format – the tabular serialization format of the Abstract Model
- ISA-JSON format – the JSON serialization format of the Abstract Model.
The specifications are licensed under CC BY-SA 4.0 , and you can cite the specifications with:
Sansone, Susanna-Assunta, Rocca-Serra, Philippe, Gonzalez-Beltran, Alejandra, Johnson David & the ISA Community. (2016, October 28). ISA Model and Serialization Specifications 1.0. Zenodo. http://doi.org/10.5281/zenodo.163640.
To view the latest version online, please visit http://isa-specs.readthedocs.io/en/latest/
